Jarque–Bera test
In statistics, the Jarque–Bera test is a goodness-of-fit test of whether sample data have the skewness and kurtosis matching a normal distribution. The test is named after Carlos Jarque and Anil K. Bera. The test statistic JB is defined as
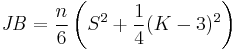
where n is the number of observations (or degrees of freedom in general); S is the sample skewness, and K is the sample kurtosis:

where 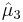 and
and 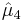 are the estimates of third and fourth central moments, respectively,
are the estimates of third and fourth central moments, respectively, 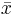 is the sample mean, and
is the sample mean, and 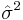 is the estimate of the second central moment, the variance.
is the estimate of the second central moment, the variance.
If the data come from a normal distribution, the JB statistic asymptotically has a chi-squared distribution with two degrees of freedom, so the statistic can be used to test the hypothesis that the data are from a normal distribution. The null hypothesis is a joint hypothesis of the skewness being zero and the excess kurtosis being zero. Samples from a normal distribution have an expected skewness of 0 and an expected excess kurtosis of 0 (which is the same as a kurtosis of 3). As the definition of JB shows, any deviation from this increases the JB statistic.
For small samples the chi-squared approximation is overly sensitive, often rejecting the null hypothesis when it is in fact true. Furthermore, the distribution of p-values departs from a uniform distribution and becomes a right-skewed uni-modal distribution, especially for small p-values. This leads to a large Type I error rate. The table below shows some p-values approximated by a chi-squared distribution that differ from their true alpha levels for small samples.
-
Calculated p-value equivalents to true alpha levels at given sample sizes True α level 20 30 50 70 100 .1 .307 .252 .201 .183 .1560 .05 .1461 .109 .079 .067 .062 .025 .051 .0303 .020 .016 .0168 .01 .0064 .0033 .0015 .0012 .002
(These values have been approximated by using Monte Carlo simulation in Matlab)
In MATLAB's implementation, the chi-squared approximation for the JB statistic's distribution is only used for large sample sizes (> 2000). For smaller samples, it uses a table derived from Monte Carlo simulations in order to interpolate p-values.[1]
History
Considering normal sampling, and √β1 and β2 contours, Bowman & Shenton (1975) noticed that the statistic JB will be asymptotically χ2(2)-distributed; however they also noted that “large sample sizes would doubtless be required for the χ2 approximation to hold”. Bowman and Shelton did not study the properties any further, preferring D’Agostino’s K-squared test.
Around 1979, Anil Bera and Carlos Jarque while working on their dissertations on regression analysis, have applied the Lagrange multiplier principle to the Pearson family of distributions to test the normality of unobserved regression residuals and found that the JB test was asymptotically optimal (although the sample size needed to “reach” the asymptotic level was quite large). In 1980 the authors published a paper (Jarque & Bera 1980), which treated a more advanced case of simultaneously testing the normality, homoscedasticity and absence of autocorrelation in the residuals from the linear regression model. The JB test was mentioned there as a simpler case. A complete paper about the JB Test was published in the International Statistical Review in 1987 dealing with both testing the normality of observations and the normality of unobserved regression residuals, and giving finite sample significance points.
References
- ^ "Analysis of the JB-Test in MATLAB". MathWorks. http://www.mathworks.com/access/helpdesk/help/toolbox/stats/jbtest.html. Retrieved May 24, 2009.
- Bowman, K.O.; Shenton, L.R. (1975). "Omnibus contours for departures from normality based on √b1 and b2". Biometrika 62 (2): 243–250. JSTOR 2335355.
- Jarque, Carlos M.; Bera, Anil K. (1980). "Efficient tests for normality, homoscedasticity and serial independence of regression residuals". Economics Letters 6 (3): 255–259. doi:10.1016/0165-1765(80)90024-5.
- Jarque, Carlos M.; Bera, Anil K. (1981). "Efficient tests for normality, homoscedasticity and serial independence of regression residuals: Monte Carlo evidence". Economics Letters 7 (4): 313–318. doi:10.1016/0165-1765(81)90035-5.
- Jarque, Carlos M.; Bera, Anil K. (1987). "A test for normality of observations and regression residuals". International Statistical Review 55 (2): 163–172. JSTOR 1403192.
- Judge; et al. (1988). Introduction and the theory and practice of econometrics (3rd ed.). pp. 890–892.
Implementations
- ALGLIB includes implementation of the Jarque–Bera test in C++, C#, Delphi, Visual Basic, etc.
- gretl includes an implementation of the Jarque–Bera test
- R includes implementations of the Jarque–Bera test: jarque.bera.test in package tseries, for example, and jarque.test in package moments.
- MATLAB includes implementation of the Jarque–Bera test, the function "jbtest".
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||